![]()
This is my entry to the Emacs Carnvial - Obscure Packages.
It's funny to say that Transient is an obscure package not just because it's now bundled in Emacs, but also because one of the killer apps in Emacs – Magit – uses it. But how many people make their own Transient menus? It's easy and it's powerful.
In my configuration, I have a hard time finding keystrokes that I can remember that aren't already taken. And how do I remember them? How do I remember them? Well I have solved that problem with making Transient menus. They aren't hard – you really don't even have to know Elisp to make them.
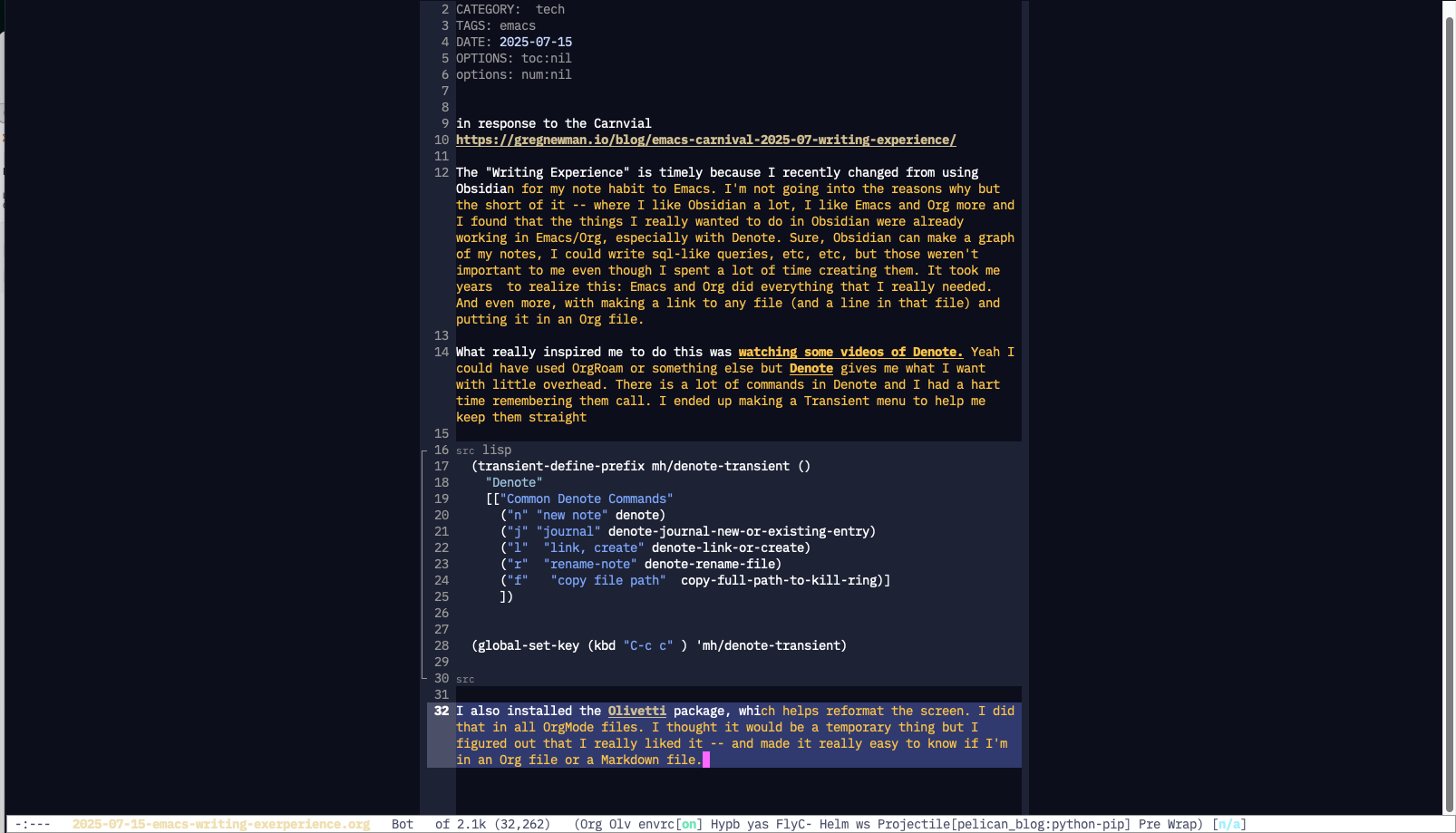
I'm no expert but here is an actual Transient example from my own config. C-c c started out as my shortcut to Denote but now it's morphed into "Mike's customized packages"
(transient-define-prefix mh/denote-transient ()
"Denote"
[["Common Denote Commands"
("n" "new note" denote)
("j" "journal" denote-journal-new-or-existing-entry)
("l" "link, create" denote-link-or-create)
("m" "mark" org-remark-mark-yellow)
("E" "email search" helm-notmuch)
("f" "find note" mh/helm-denote-find-files)
("r" "rename-note" denote-rename-file)
("F" "copy file path" copy-full-path-to-kill-ring)
("w" "Explore Random Note" denote-explore-random-note)
("p" "lsp" eglot-transient-menu)
]
["less common\n "
("J" "Janitor" mh/denote-janitor-transient)
("e" "Explore" mh/denote-explore-transient)
("b" "show backlinks" denote-backlinks)
("d" "dired filter" denote-sort-dired)
("g" "ag notes" mh/helm-ag-org-wiki)
("k" "search old vaults" my-xeft-transient)]])
(global-set-key (kbd "C-c c" ) 'mh/denote-transient)
Note that the format is "key" "Label" "function". Any function will do. even other Transients! One of my favorite things is to make another Transient menu in another config file and just call reference it in my main one. I like this a lot because I only have to remember one shortcut C-c c and then all my other customizations are listed. If I remember what I need, I just quickly hit it otherwise I look at the label.
It's funny how this is probably something Emacs people use most everyday via Magit but do not implement their own Transient menus themselves. They are easy to put together, and powerful.